Spark 3 新特性
AQE(Adaptive Query Execution,自适应查询执行)
为什么需要 AQE
在 AQE 之前, Spark 分别推出了 RBO(Rule Based Optimization,基于规则的优化)、CBO(Cost Based Optimization,基于成本的优化)
RBO
往往基于一些数据库领域已有的应用经验,通过一些规则和策略实现优化,如谓词下推、列剪枝,本质上还是经验主义,局限很大
- 谓词下推: 将查询语句中的过滤表达式计算尽可能下推到距离数据源最近的地方,以尽早完成数据的过滤,进而显著地减少数据传输或计算的开销, 参考 TiDB 谓词下推
- 列剪枝: 减少读取不必要的属性列,对列式数据库提高扫描效率,减少网络、内存数据量消耗
CBO
基于数据表的统计信息(如表大小、数据列分布)来选择优化策略,但也存在较大的局限
- 适用面太窄,仅支持注册到 Hive Metastoren的数据表,但实际应用场景中,数据源往往是分布式文件系统存储,如CSV、ORC、Parquet等
- 统计信息效率比较低,对于注册到 Hive Metastore 的数据表,开发者需要调用 ANALYZE TABLE COMPUTE STATISTICS 语句收集统计信息
- 依旧是静态优化,生成计划开始执行后,不再会改变,做不到跟随数据动态分布进行调整适配执行计划
AQE 是什么
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化, 在条件允许的情况下,优化决策会分别作用到逻辑计划和物理计划
AQE 优化机制触发的时机是 Shuffle Map 阶段执行完毕,AQE 优化的频次与执行计划中 Shuffle 的次数一致。也就是说,如果查询语句没有 Shuffle 操作,那么 Spark SQL 是不会触发 AQE 的
AQE 如何统计信息
Spark shuffle 中每个 Map Task 结束后会输出以 .data 为 后缀的数据文件和以 .index 为后缀的索引文件, 这些文件统称为中间文件,写入逻辑参考源码类:LocalDiskShuffleMapOutputWriter.scala 和 BlockId.scala
@DeveloperApi
case class ShuffleDataBlockId(shuffleId: Int, mapId: Long, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".data"
}
@DeveloperApi
case class ShuffleIndexBlockId(shuffleId: Int, mapId: Long, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".index"
}
每个 data 文件的大小、空文件数量与占比、每个 Reduce Task 对应的分区大小,所有这些基于中间文件的统计值构成了 AQE 进行优化的信息来源
AQE 既定的规则和策略

AQE 三大特性
- Join 策略调整:如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联就会从 Shuffle Sort Merge Join 降级(Demote)为执行效率更高的 Broadcast Hash Join。
- 自动分区合并:在 Shuffle 过后,Reduce Task 数据分布参差不齐,AQE 将自动合并过小的数据分区。
- 自动倾斜处理:结合配置项,AQE 自动拆分 Reduce 阶段过大的数据分区,降低单个 Reduce Task 的工作负载
join 策略调整
涉及了DemoteBroadcastHashJoin 和 OptimizeLocalShuffleReader 规则策略
DemoteBroadcastHashJoin 规则:
- 空文件占比小于配置项 spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin
- 中间文件尺寸总和小于广播阈值 spark.sql.autoBroadcastJoinThreshold (这条是 Broadcast join 条件)
满足了以上条件,会把 Shuffle Joins 降级为 Broadcast Joins, 但仅适用于 Shuffle Sort Merge Join 这种关联机制,其他机制如 Shuffle Hash Join、Shuffle Nested Loop Join 都不支持
private def shouldDemote(plan: LogicalPlan): Boolean = plan match {
case LogicalQueryStage(_, stage: ShuffleQueryStageExec) if stage.resultOption.isDefined
&& stage.mapStats.isDefined =>
val mapStats = stage.mapStats.get
val partitionCnt = mapStats.bytesByPartitionId.length
val nonZeroCnt = mapStats.bytesByPartitionId.count(_ > 0)
partitionCnt > 0 && nonZeroCnt > 0 &&
(nonZeroCnt * 1.0 / partitionCnt) < conf.nonEmptyPartitionRatioForBroadcastJoin
case _ => false
}
OptimizeLocalShuffleReader 规则
配置项:
spark.sql.adaptive.localShuffleReader.enabled, 默认为 True
/**
* A rule to optimize the shuffle reader to local reader iff no additional shuffles
* will be introduced:
* 1. if the input plan is a shuffle, add local reader directly as we can never introduce
* extra shuffles in this case.
* 2. otherwise, add local reader to the probe side of broadcast hash join and
* then run `EnsureRequirements` to check whether additional shuffle introduced.
* If introduced, we will revert all the local readers.
*/
Shuffle 大致可以分位 Map / Reduce 两个阶段,而 AQE 依赖于 Shuffle MapTask 生成的中间文件统计信息,这意味着其必须依赖 Shuffle Map阶段所有任务都完成。 而在常规的 Shuffle 计算流程中,Reduce 阶段的计算需要跨节点访问中间文件拉取数据分片。如果遵循常规步骤,即便 AQE 在运行时把 Shuffle Sort Merge Join 降级为 Broadcast Join,大表的中间文件还是需要通过网络进行分发,而采取 OptimizeLocalShuffleReader 策略则可以省去 Shuffle 常规步骤中的网络分发,Reduce Task 可以就地读取本地节点(Local)的中间文件,完成与广播小表的关联操作
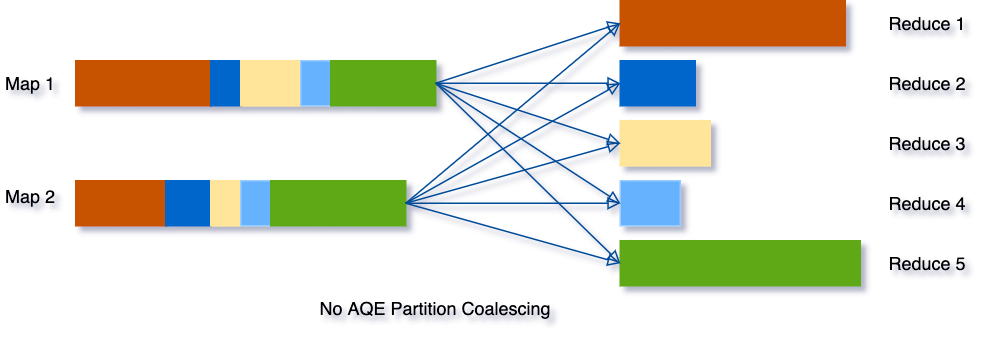
自动分区合并 ( CoalesceShufflePartitions 策略)
配置项:
spark.sql.adaptive.coalescePartitions.enabled, 默认为 True
原理:
在 Reduce 阶段,当 Reduce Task 从全网把数据分片拉回,AQE 按照分区编号的顺序,依次把小于目标尺寸的分区合并在一起
目标分区尺寸由以下参数共同决定:
spark.sql.adaptive.advisoryPartitionSizeInBytes,由开发者指定分区合并后的推荐尺spark.sql.adaptive.coalescePartitions.minPartitionNum,分区合并后,分区数不能低于该值, 假如没设置该值则取spark.default.parallelism值

自动倾斜处理 (OptimizeSkewedJoin 策略)
在 Reduce 阶段,当 Reduce Task 所需处理的分区尺寸大于一定阈值时,利用 OptimizeSkewedJoin 策略,在 Reduce 阶段,同一个 Executor 内部,本该由一个 Task 去处理的大分区,会被 AQE 拆成多个小分区并交由多个 Task 去计算,平衡 Task 之间的计算负载
倾斜分区和拆分粒度由以下这些配置项决定:
spark.sql.adaptive.skewJoin.skewedPartitionFactor,判定倾斜的膨胀系数spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,判定倾斜的最低阈值spark.sql.adaptive.advisoryPartitionSizeInBytes,以字节为单位,定义拆分粒度
/**
* A rule to optimize skewed joins to avoid straggler tasks whose share of data are significantly
* larger than those of the rest of the tasks.
*
* The general idea is to divide each skew partition into smaller partitions and replicate its
* matching partition on the other side of the join so that they can run in parallel tasks.
* Note that when matching partitions from the left side and the right side both have skew,
* it will become a cartesian product of splits from left and right joining together.
*
* For example, assume the Sort-Merge join has 4 partitions:
* left: [L1, L2, L3, L4]
* right: [R1, R2, R3, R4]
*
* Let's say L2, L4 and R3, R4 are skewed, and each of them get split into 2 sub-partitions. This
* is scheduled to run 4 tasks at the beginning: (L1, R1), (L2, R2), (L3, R3), (L4, R4).
* This rule expands it to 9 tasks to increase parallelism:
* (L1, R1),
* (L2-1, R2), (L2-2, R2),
* (L3, R3-1), (L3, R3-2),
* (L4-1, R4-1), (L4-2, R4-1), (L4-1, R4-2), (L4-2, R4-2)
*
* Note that, when this rule is enabled, it also coalesces non-skewed partitions like
* `CoalesceShufflePartitions` does.
*/
不足
- 只能做到 Task 之间的计算负载平衡,并不能解决不同 Executors 之间的负载均衡问题

如上图,假设有个 Shuffle 操作,它的 Map 阶段有 3 个分区,Reduce 阶段有 4 个分区。4 个分区中的两个都是倾斜的大分区,而且这两个倾斜的大分区刚好都分发到了 Executor 0,尽管两个大分区被拆分,但横向来看,整个作业的主要负载还是落在了 Executor 0 的身上。Executor 0 的计算能力依然是整个作业的瓶颈
-
不一定能减少计算开销
如下图,对于在 Shuffle 操作中进行 Join 的两张表,如果表 1 存在数据倾斜,表 2 不倾斜,那在关联的过程中,AQE 除了对表 1 做拆分之外,还需要对表 2 对应的数据分区做复制,来保证关联关系不被破坏

那么如源码注释所说,假如两张表都存在数据倾斜的情况,那么将会采用笛卡尔积计算,意味着假如左表拆成 M 个分区,右表拆出 N 各分区,那么每张表最终都需要保持 M x N 份分区数据, 才能保证关联逻辑的一致性。当 M 和 N 逐渐变大时,AQE 处理数据倾斜所需的计算开销将会面临失控的风险
总结
当应用场景中的数据倾斜比较简单,比如虽然有倾斜但数据分布相对均匀,或是关联计算中只有一边倾斜,我们完全可以依赖 AQE 的自动倾斜处理机制。但是,当我们的场景中数据倾斜变得复杂,比如数据中不同 Key 的分布悬殊,或是参与关联的两表都存在大量的倾斜,我们就需要衡量 AQE 的自动化机制与手工处理倾斜之间的利害得失
DPP (动态分区剪裁)
基于运行时(run time)推断出来的信息来进一步进行分区裁剪,从而减少事实表中数据的扫描量、降低 I/O 开销,提升执行性能
例如,我们在进行事实表和维度表的Join过程中,把事实表中的无效数据进行过滤:
SELECT * FROM dim
JOIN fact
ON (dim.col = fact.col)
WHERE dim.col = 'dummy'
当SQL满足DPP的要求后,会根据关联关系dim.col = fact.col,通过维度表的列传导到事实表的col字段,只扫描事实表中满足条件的部分数据,就可以做到减少数据扫描量,提升I/O效率。
但是使用DPP的前提条件比较苛刻,需要满足以下条件:
- 事实表必须是分区表
- 只支持等值Join
- 维度表过滤之后的数据必须小于广播阈值:
spark.sql.autoBroadcastJoinThreshold