数仓系列-数据建模方法
部分内容参考自: 数据仓库的建设方法篇
数据模型的基本概念
数据模型是抽象描述现实世界的一种工具和方法,是通过抽象的实体及实体之间联系的形式,来表示现实世界中事务的相互关系的一种映射。在这里,数据模型表现的抽象的是实体和实体之间的关系,通过对实体和实体之间关系的定义和描述,来表达实际的业务中具体的业务关系,分为以下几个层次:
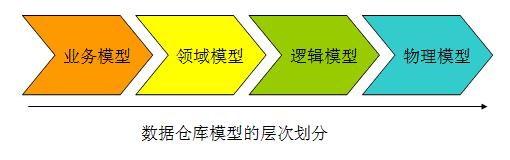
通过上面的图形,我们能够很容易的看出在整个数据仓库得建模过程中,我们需要经历一般四个过程:
-
业务建模,生成业务模型,主要解决业务层面的分解和程序化。
-
领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。
-
逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
-
物理建模,生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题
范式建模
在数据仓库的模型设计中目前一般采用第三范式,它有着严格的数学定义。从其表达的含义来看,一个符合第三范式的关系必须具有以下三个条件 :
- 每个属性值唯一,不具有多义性 ;
- 每个非主属性必须完全依赖于整个主键,而非主键的一部分 ;
- 每个非主属性不能依赖于其他关系中的属性,因为这样的话,这种属性应该归到其他关系中去
维度建模
最简单的描述就是,按照事实表,维表来构建数据仓库,数据集市。如星型模式、雪花模型等
星型模型(Star-schema)

上图的这个架构中是典型的星型架构。星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余
特点
-
只有一个事实表,并且每一个维度有一个单独的表。
-
事实表中的每一个元组都是一个外键指向维度表的主键。
-
每一个维度表的列是组成这个维度的所有属性
-
事实表与维度表通过主键外键相关联,维度表之间没有关联,就像很多星星围绕在一个恒星周围,故取名为星形模型。
优点
-
星形模型是最简单, 也是最常用的模型。
-
由于星形模型只有一张大表, 因此它相比于其他模型更适合于大数据处理。
-
其他模型可以通过一定的转换, 变为星形模型
雪花模型(Snow Schema)
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
雪花模型是对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表

虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低, 所以一般不是很常用
数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。而雪花模型相比星型虽然更规范一些,但是不太容易理解,维护成本也比较高,而且性能方面需要关联多层维表,性能也比星型模型要低,反而在关系型数据库中如MySQL,Oracle中比较常见。
星座模型(Fact Constellation)
星座模型是更复杂的模型,其中包含了多个事实表,而维度表是公用的,可以共享多个事实表共享维表,这种模式可以看作星座模式集,因此称作星系模式(galaxy schema),或者事实星座(fact constellation)

维度建模的过程
四步走: 选择业务过程 => 确认粒度 => 确认维度 => 确认事实
以招聘网站为例,假设我们需要构建一个职位投递分析的数据模型:
1、 选择业务过程
一般建立数仓都是根据业务线来的,一条业务线又会包括很多业务流程,所以我们需要首先根据业务流程和业务需求来划分业务域。比如在招聘业务中,我们需要考虑的业务过程有企业职位发布、简历投递、面试记录等
2、声明粒度
建议先从原子粒度,也就是最细粒度开始设计,因为业务前期往往需求是多变的,但维度建模中要求我们,在同一事实表中,必须具有相同的粒度,而且针对有明确需求的数据,我们也可以通过建立针对需求的上卷汇总粒度来解决,相当于先打好地基,扩建起来也方便了。 比如以简历投递过程来说:
- 最细粒度:每次投递行为(一个求职者投递一个职位为一条记录)
- 可能的汇总粗粒度:
- 每天每个职位的投递汇总
- 每个求职者在每个公司的投递汇总
- 每个职位类别的月度投递汇总
3、确认维度
基于业务需求,确定需要分析的维度。对于简历投递分析,主要维度包括:
- 时间维度:投递时间(年、月、日、时段、工作日/节假日)
- 求职者维度:
- 基础属性:年龄、性别、学历
- 工作属性:工作年限、目前状态
- 技能特征:技能标签、职业方向
- 职位维度:
- 职位属性:职位名称、职位类别、工作城市
- 要求属性:学历要求、经验要求、薪资范围
- 企业维度:
- 企业属性:企业名称、企业规模、行业领域
- 区域属性:总部城市、办公地点
4、确认事实
确定需要度量的指标,对于简历投递分析:
- 计数类事实:
- 投递次数
- 简历被查看次数
- 进入面试次数
- 比率类事实:
- 简历查看率
- 面试邀请率
- 投递响应时长
- 派生事实:
- 简历匹配度(基于职位要求计算)
- 活跃度指数(基于投递行为计算)
基于以上分析,我们可以构建以下事实表:
-
职位投递事实表(主事实表)
- 事实:投递次数、投递时间
- 外键:求职者ID、职位ID、企业ID、时间ID
- 特点:记录原子级投递行为
-
简历处理事实表
- 事实:简历查看次数、查看时长、面试邀请次数
- 外键:投递ID、HR_ID、时间ID
- 特点:跟踪简历处理过程
-
面试事实表
- 事实:面试次数、面试时长、面试评分
- 外键:投递ID、面试官ID、时间ID
- 特点:记录面试相关指标
-
匹配度事实表(派生事实表)
- 事实:简历匹配度、技能匹配度、经验匹配度
- 外键:求职者ID、职位ID
- 特点:存储计算后的匹配指标
关联维度表:
- 时间维度表
- 求职者维度表
- 职位维度表
- 企业维度表
- HR维度表
- 面试官维度表
这样的模型设计能够支持多种分析场景,如:
- 不同城市的职位投递热度分析
- 不同职位类别的简历匹配率分析
- 企业招聘效率分析
- 求职者求职偏好分析
总结
维度建模法的优点: 维度建模非常直观,紧紧围绕着业务模型,可以直观的反映出业务模型中的业务问题。不需要经过特别的抽象处理,即可以完成维度建模
维度建模法的缺点:
-
由于在构建星型模式之前需要进行大量的数据预处理,因此会导致大量的数据处理工作。
-
当业务发生变化,需要重新进行维度的定义时,往往需要重新进行维度数据的预处理。而在这些与处理过程中,往往会导致大量的数据冗余。
-
如果只是依靠单纯的维度建模,不能保证数据来源的一致性和准确性,而且在数据仓库的底层,不是特别适用于维度建模的方法。
维度建模的领域主要适用于数据集市层,它的最大的作用其实是为了解决数据仓库建模中的性能问题。维度建模很难能够提供一个完整地描述真实业务实体之间的复杂关系的抽象方法。