RDD总结
抽象类RDD源码分析
基本定义
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging
变量定义
-
id: 当前RDD的唯一身份标识,val id: Int = sc.newRddId() -
storageLevel: 当前RDD的存储级别,private var storageLevel: StorageLevel = StorageLevel.NONE -
creationSite: 创建当前RDD的用户代码(e.g.textFile,parallelize) -
scope: 当前RDD的操作作用域, 有一个withScope调用, 就像是一个 AOP,嵌入到所有RDD 的转换和操作的函数中,RDDOperationScope会把调用栈记录下来,用于绘制Spark UI的 DAG -
checkpointData: 当前RDD的检查点数据 -
checkpointAllMarkedAncestors: 是否对所有标记了需要保存检查点的祖先保存检查点 -
doCheckpointCalled: 是否已经调用了doCheckPoint方法设置检查点, 此属性可以阻止对RDD多次设置检查点 -
stateLock: 用于锁定RDD的可变状态, 它被定义为一个常量整数,private val stateLock = new Integer(0), 联想到操作系统中的信号量机制,在进行可变操作时会先执行stateLock.synchronized{}加锁, 那么为什么不直接用this给对象加锁呢?源码里是这样解释的:/** * Lock for all mutable state of this RDD (persistence, partitions, dependencies, etc.). We do * not use `this` because RDDs are user-visible, so users might have added their own locking on * RDDs; sharing that could lead to a deadlock. * * One thread might hold the lock on many of these, for a chain of RDD dependencies; but * because DAGs are acyclic, and we only ever hold locks for one path in that DAG, there is no * chance of deadlock. * * The use of Integer is simply so this is serializable -- executors may reference the shared * fields (though they should never mutate them, that only happens on the driver). */大致意思就是因为RDD都是用户可见的, 用户线程和spark的调度器线程可以同时访问和修改RDD依赖项和分区, 所以用户可能在某些时候会主动加锁,而RDD是一个并行数据结构,大家都去抢夺锁的话就有可能会产生死锁(理解的比较片面,后续需要回顾理解, 详情见SPARK-28917)
-
barrier: 一个还在实验的特性
一些函数方法定义
RDD采用了模版方法的模式设计,抽象类RDD定义了模版方法及一些接口
一些接口
compute: 对RDD的分区进行计算getPartitions: 获取当前RDD的所有分区getDependencies: 获取当前RDD的所有依赖getPreferredLocations: 获取某一分区的偏好位置
一些模版方法
partitions方法 用于获取RDD的分区数组
final def partitions: Array[Partition] = {
checkpointRDD.map(_.partitions).getOrElse {
if (partitions_ == null) {
stateLock.synchronized {
if (partitions_ == null) {
partitions_ = getPartitions
partitions_.zipWithIndex.foreach {...}
}
}
}
partitions_
}
}
可以看出, partitions方法查找分区数组的优先级为:
从CheckPoint查找 -> 读取partitions_属性 -> 调用getPartitions方法获取
dependencies方法 用于获取当前RDD的所有依赖的序列
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
stateLock.synchronized {
if (dependencies_ == null) {
dependencies_ = getDependencies
}
}
}
dependencies_
}
}
其他方法
getStorageLevel返回当前RDD的StorageLevelgetNumPartitions获取这个RDD的分区数getNarrowAncestors利用DFS算法遍历当前RDD的依赖树获取其祖先依赖中属于窄依赖的RDD序列
private[spark] def getNarrowAncestors: Seq[RDD[_]] = {
val ancestors = new mutable.HashSet[RDD[_]]
def visit(rdd: RDD[_]): Unit = {
val narrowDependencies = rdd.dependencies.filter(_.isInstanceOf[NarrowDependency[_]])
val narrowParents = narrowDependencies.map(_.rdd)
val narrowParentsNotVisited = narrowParents.filterNot(ancestors.contains)
narrowParentsNotVisited.foreach { parent =>
ancestors.add(parent)
visit(parent)
}
}
visit(this)
// In case there is a cycle, do not include the root itself
ancestors.filterNot(_ == this).toSeq
}
还有一些基本算子
为什么需要RDD
从以下四个点解释
数据处理模型
通常数据处理的模型包括迭代计算、关系查询、MapReduce、流式处理等。Hadoop采用MapReduce模型,Storm采用流式处理模型,而Spark借助RDD实现了以上所有模型
依赖划分原则
一个RDD包含一个或多个分区, 每个分区实际上是一个数据集合的片段, RDD之间通过依赖关系串联起来构建成DAG.
依赖划分为NarrowDependcy和ShuffleDependcy两种, 参考:
RDD的依赖
Spark宽依赖与窄依赖
数据处理效率
ShuffleDependcy所依赖的上游RDD的计算过程允许在多个节点并发执行, 数据量大的时候可以通过适当调整分区数量,能有效提高Spark的数据处理效率
容错处理
传统关系型数据库往往采用日志记录的方式来容灾,Hadoop通过将数据备份到其他机器容灾。Spark则通过RDD依赖组成的DAG直接重新调度计算失败的Task,成功的Task可以从CheckPoint中读取。
(:在流式计算中,Spark需要通过记录日志和CheckPoint进行数据恢复
参考
What is Spark RDD and Why Do We Need it?
RDD的依赖
Dependency抽象类
Spark使用Dependency来表示RDD之间的依赖关系,其定义如下:
DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
抽象类Dependendcy只定义了一个名叫rdd的方法, 此方法返回当前依赖的RDD
依赖又分为窄依赖(NarrowDependcy)和宽依赖(ShuffleDependcy)
窄依赖(NarrowDependcy)
基本定义
如果子RDD依赖于父RDD中固定的Partion分区, 其之间的依赖关系属于窄依赖, 定义如下:
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
还有两个子类OneToOneDependency 和 RangeDependency
OneToOneDependency
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
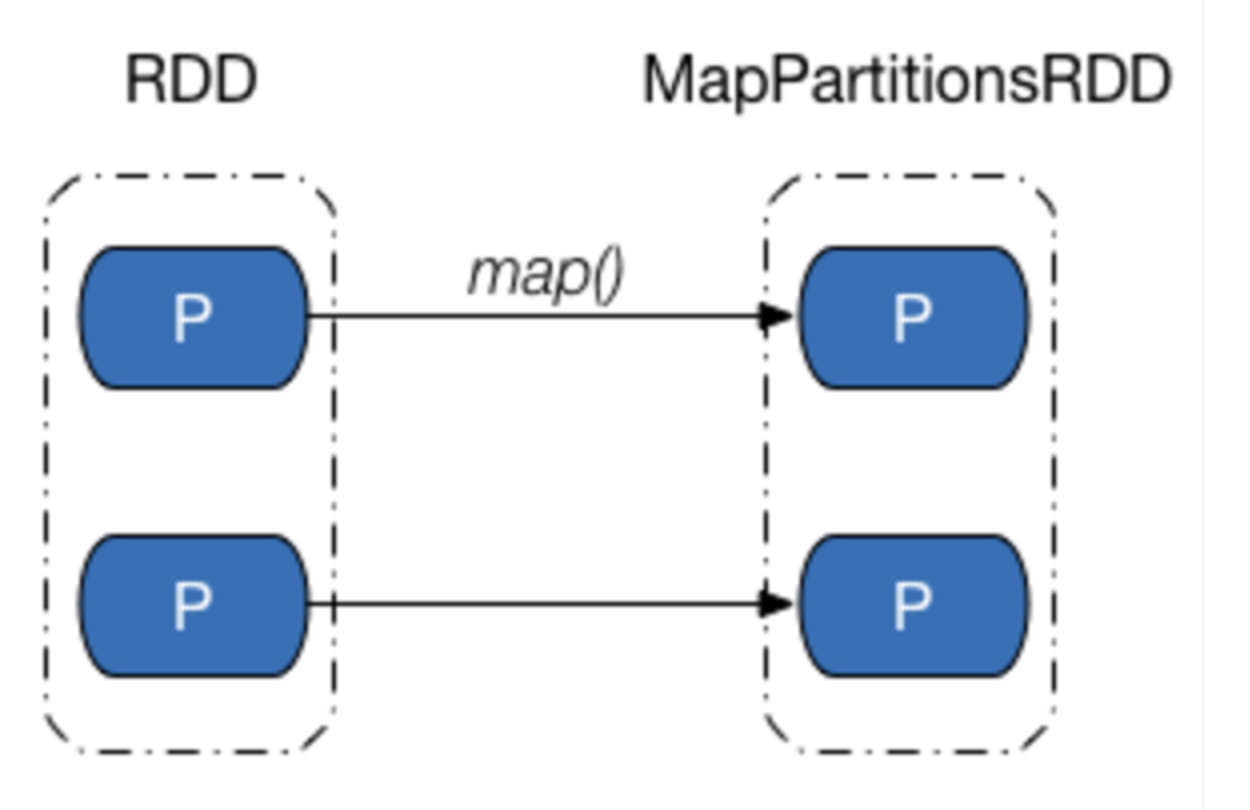
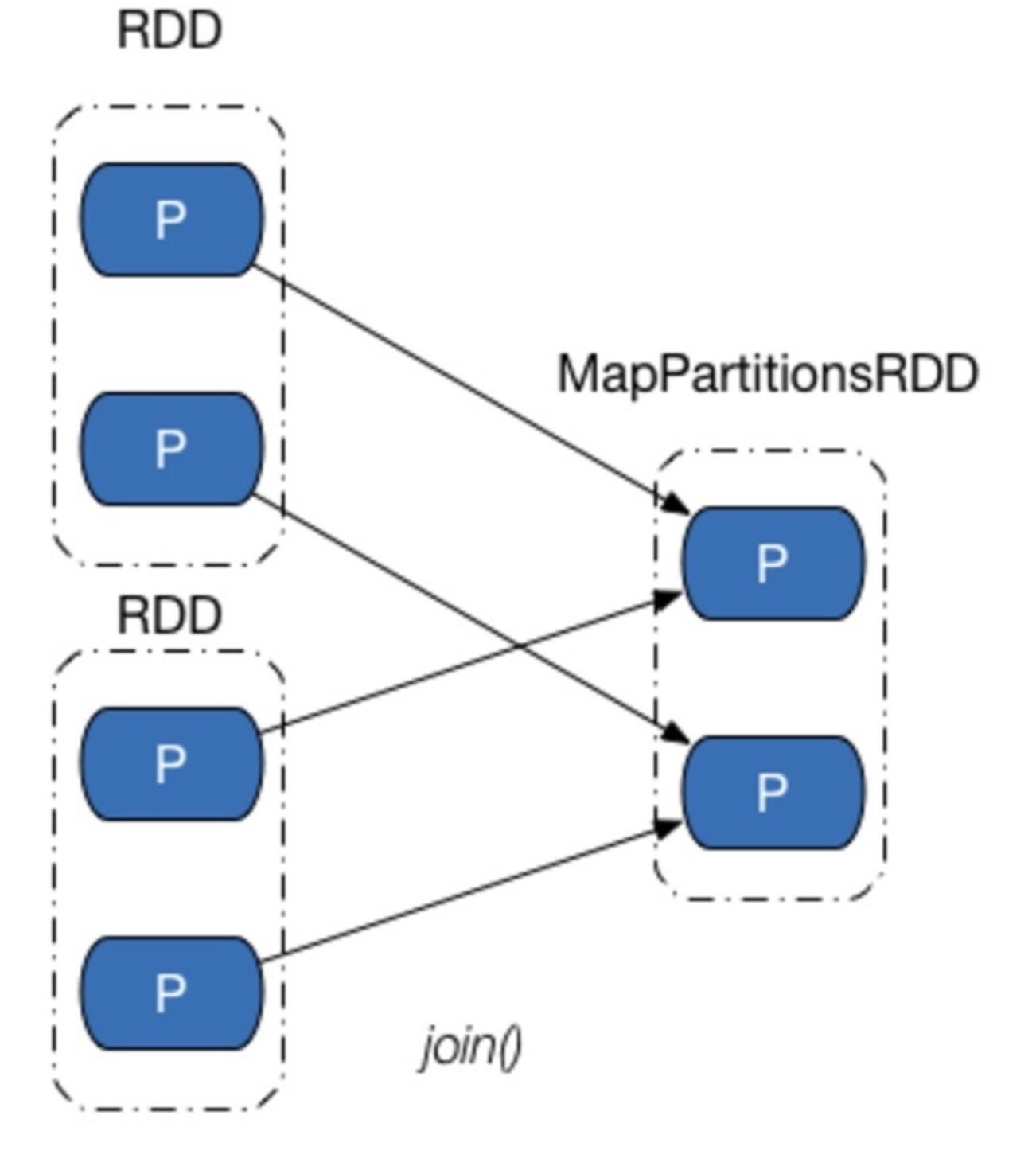
这个类重写了getParents, 直接把传递进去的id号封装成Seq返回。可以是多个子RDD, 但每一个子RDD的每一个分区和父RDD都是一对一的关系, 子RDD分区的个数和父RDD分区的个数一样, 如下两种情况
RangeDependency
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
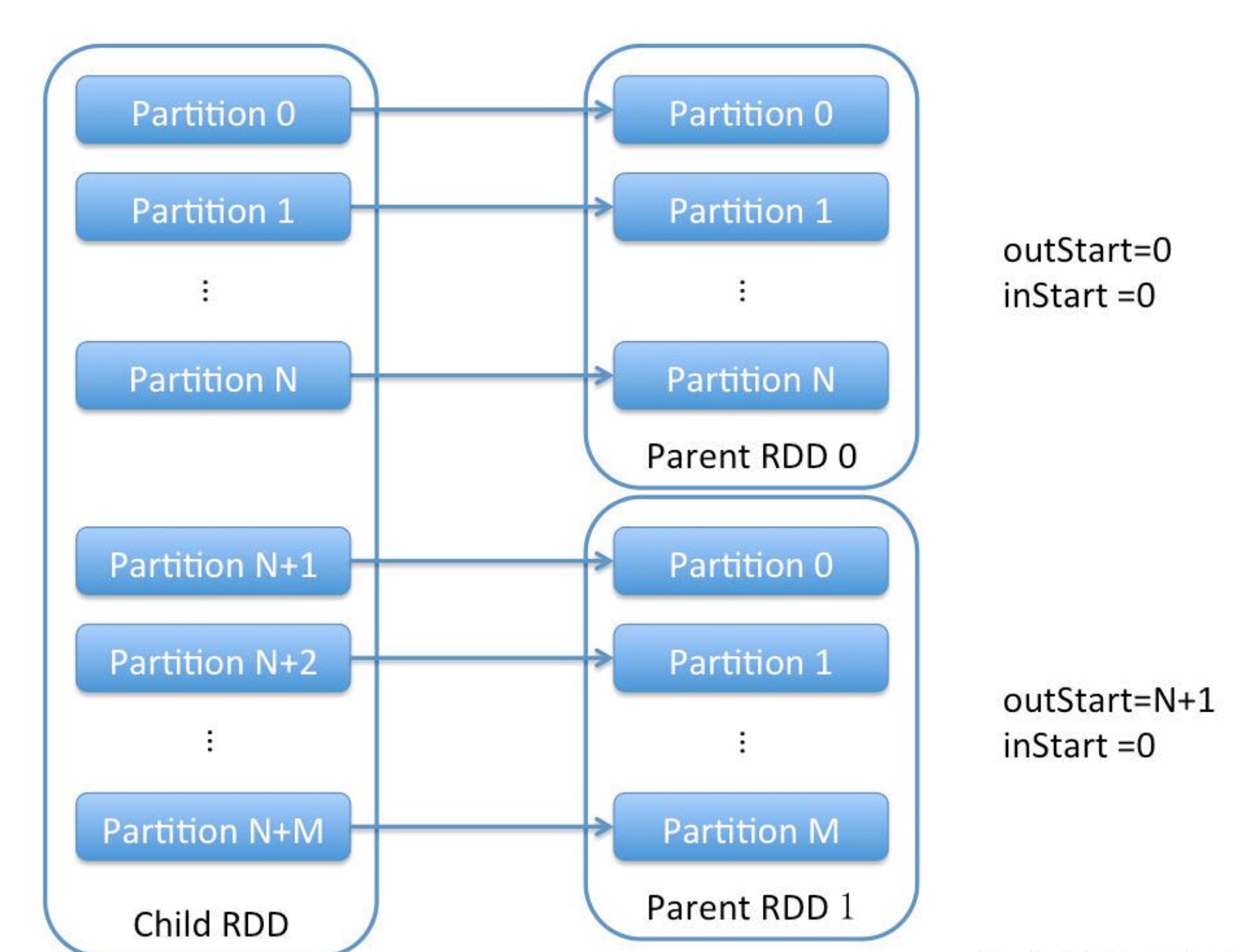
RangeDependency也是重写了getParents方法, 与OneToOneDependency不同的点在于可能有多个父RDD, 而一个子RDD的分区依赖于很多父RDD的分区, 但分区也都是一对一的关系, 即子RDD的每一个分区都且唯一对应着一个父RDD的分区, union操作中存在这种情况
宽依赖(ShuffleDependcy)
父RDD的一个分区中的数据同时被子RDD的多个分区所依赖, 就是说子RDD的分区和父RDD不再是一对一的关系, 可能是多对一的关系, 数据被切分利用
源码实现
/**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If not set
* explicitly then the default serializer, as specified by `spark.serializer`
* config option, will be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
*/
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
if (mapSideCombine) {
require(aggregator.isDefined, "Map-side combine without Aggregator specified!")
}
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
属性解释
_rdd:泛型要求必须是Product2[K, V]及其子类的RDDpartitioner:分区计算器Partitionerserializer:SparkEnv中创建的serializer,即org.apache.spark.serializer.JavaSerializer。keyOrdering:按照K进行排序的scala.math.Ordering的实现类。aggregator:对map任务的输出数据进行聚合的聚合器。mapSideCombine:是否在map端进行合并,默认为false。keyClassName:K的类名。valueClassName:V的类名。combinerClassName:组合器,将切割后的数据组合在一个RDD所使用的组合器shuffleId:当前ShuffleDependency的身份标识。shuffleHandle:当前ShuffleDependency的处理器
补充
- ShuffleDependency需要经过shuffle过程才能形成,而shuffle都是基于 PairRDD进行的,所以传入的RDD需要是key-value类型的
newShuffleId的作用是得到唯一的shufflId(每次加1)